C#如何以管理员身份运行程序
本文共 599 字,大约阅读时间需要 1 分钟。
在使用winform程序获取调用cmd命令提示符时,如果是win7以上的操作系统,会需要必须以管理员身份运行才会执行成功,否则无效果或提示错误。 比如在通过winform程序执行cmd命令时,某些情况下如果不是以管理员身份运行,则会提示命令无效。或者通过winform程序执行Windows Service 服务时,也需要以管理员身份才能调用Service服务。
下面讲解一下如何使程序获取管理员权限来运行。
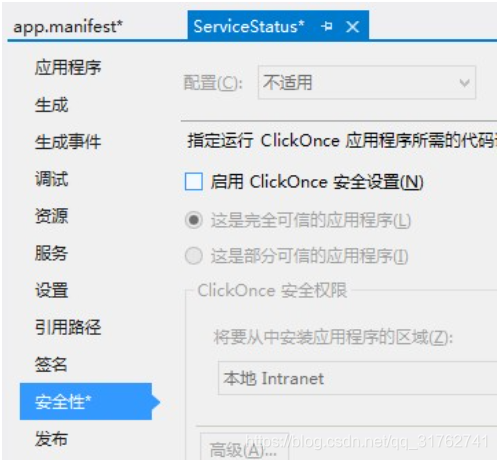
- 在Visual Studio 中–解决方案资源管理器–右键项目名称–属性,找到“安全性”选项
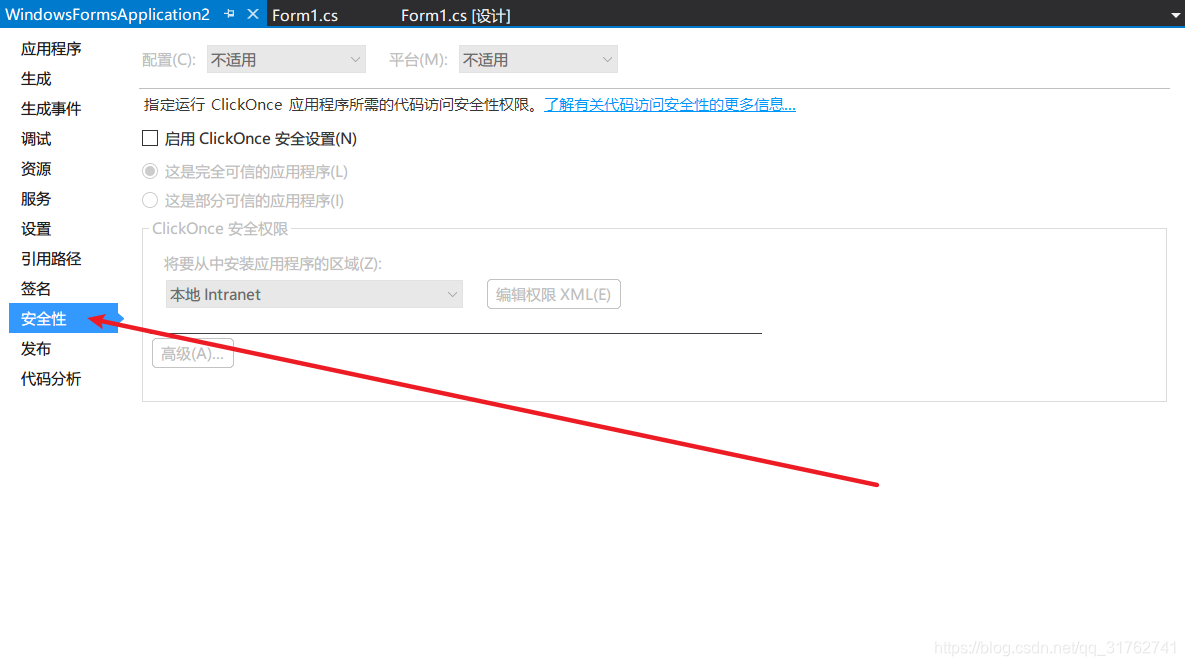
- 勾选“启用ClickOnce安全设置”
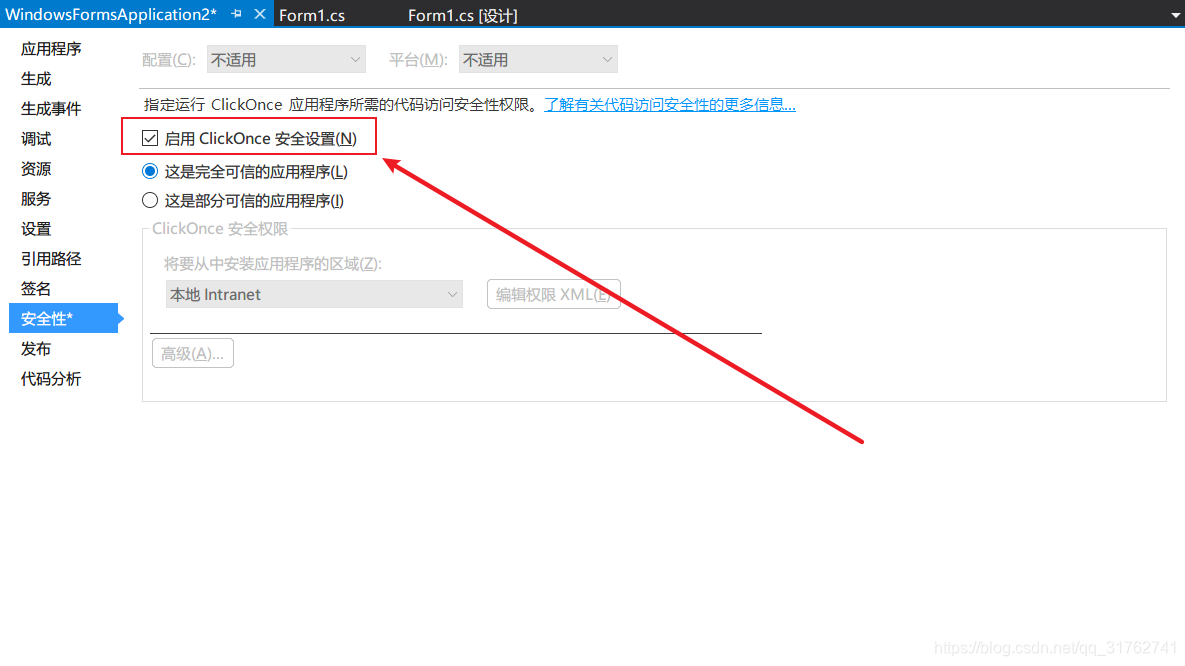
- 这时,在项目下面会多出一个“app.manifest”的文件,选中它,并找到代码段
<requestedExecutionLevel level="asInvoker" uiAccess="false" />,将其改为:<requestedExecutionLevel level="requireAdministrator" uiAccess="false" />,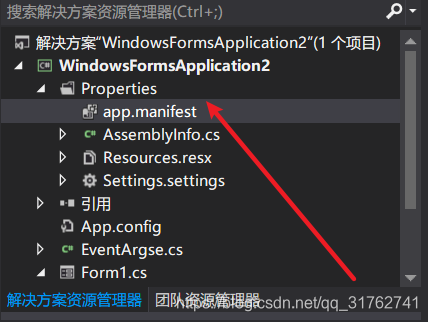 打开
打开 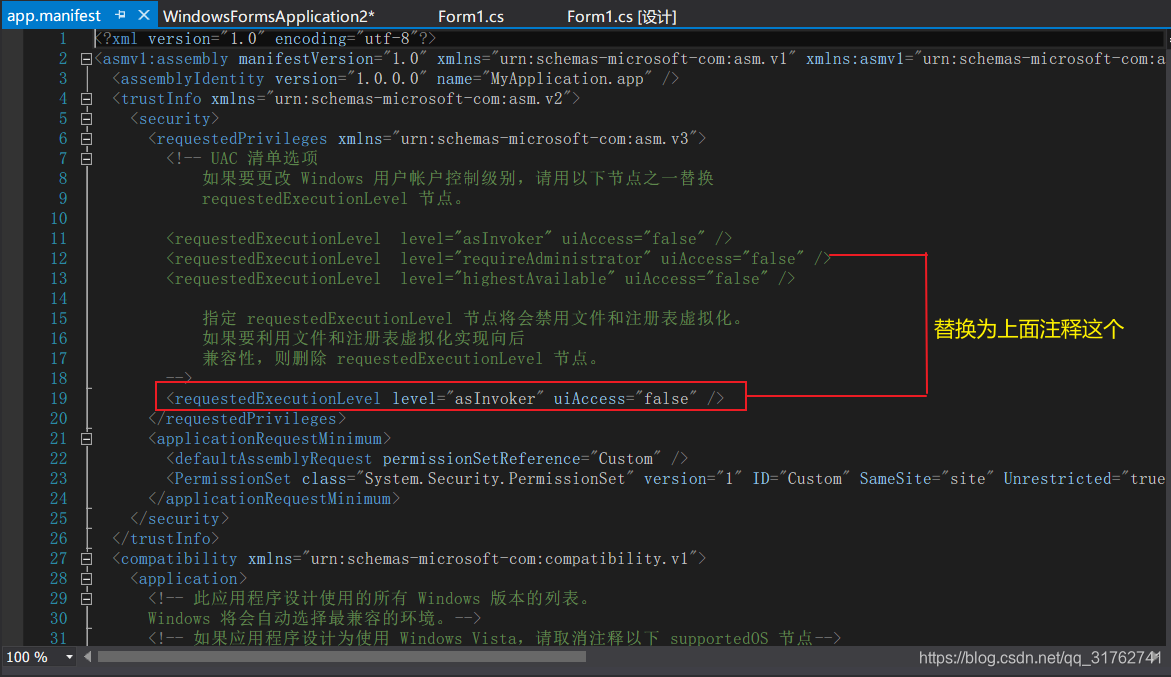
- 改正后,不要急于重新编译生成,再次打开“属性–安全性”界面, 将“启用ClickOnce安全设置”前面的勾去掉后再编译运行。 不然程序会报错无法运行。
转载地址:http://onex.baihongyu.com/
你可能感兴趣的文章
MYSQL、SQL Server、Oracle数据库排序空值null问题及其解决办法
查看>>
mysql一个字段为空时使用另一个字段排序
查看>>
MySQL一个表A中多个字段关联了表B的ID,如何关联查询?
查看>>
MYSQL一直显示正在启动
查看>>
MySQL一站到底!华为首发MySQL进阶宝典,基础+优化+源码+架构+实战五飞
查看>>
MySQL万字总结!超详细!
查看>>
Mysql下载以及安装(新手入门,超详细)
查看>>
MySQL不会性能调优?看看这份清华架构师编写的MySQL性能优化手册吧
查看>>
MySQL不同字符集及排序规则详解:业务场景下的最佳选
查看>>
Mysql不同官方版本对比
查看>>
MySQL与Informix数据库中的同义表创建:深入解析与比较
查看>>
mysql与mem_细说 MySQL 之 MEM_ROOT
查看>>
MySQL与Oracle的数据迁移注意事项,另附转换工具链接
查看>>
mysql丢失更新问题
查看>>
MySQL两千万数据优化&迁移
查看>>
MySql中 delimiter 详解
查看>>
MYSQL中 find_in_set() 函数用法详解
查看>>
MySQL中auto_increment有什么作用?(IT枫斗者)
查看>>
MySQL中B+Tree索引原理
查看>>
mysql中cast() 和convert()的用法讲解
查看>>